Exercice Octavia – Alpha / Beta / Gamma
Ce projet est un exercice pour comprendre la différence entre : - raisonnement humain (Alpha) - apprentissage automatique (Beta) - impact des erreurs de données (Gamma)
Le contexte est inspiré de l’expérience d’Asch (conformité).
Alpha – Raisonnement humain
Dans la partie Alpha, nous ne faisons pas de machine learning.
Nous utilisons un diagramme d’activité pour expliquer la logique humaine : - lire les entrées (a, b, c, d, 1, 2, 3, ref) - choisir une réponse - comparer avec la référence - décider si la réponse est correcte ou non
Objectif : expliquer la décision sans code, seulement avec la logique.
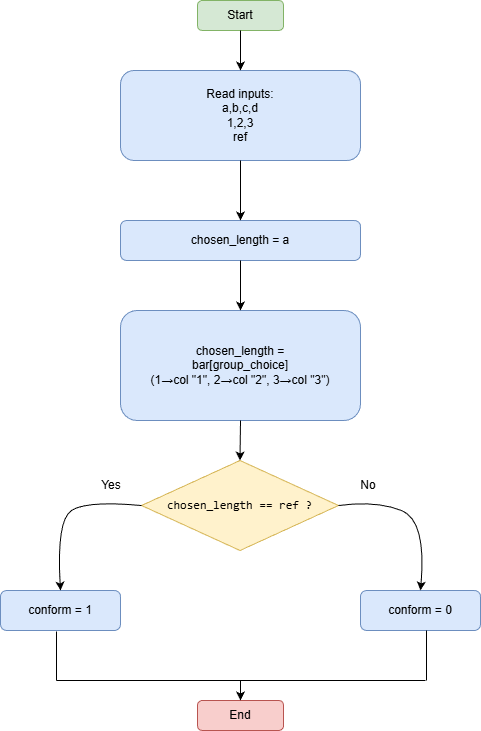
Beta – Apprentissage automatique
Dans la partie Beta, nous transformons la logique humaine en données.
Génération des données
Fichier :
Fichier : beta/generate_datasets.py
Ce script : - génère des valeurs aléatoires (1 à 10) - crée des colonnes : a, b, c, d, 1, 2, 3, ref - sauvegarde un dataset d’entraînement et un dataset de test
Ajout du label (conform)
Fichier : beta/add_label.py
Ici : - conform = 1 si a == ref - conform = 0 sinon
Nous créons les bonnes réponses pour entraîner le modèle.
Entraînement de l’arbre de décision
Fichier : beta/train_tree.py
Nous utilisons : - DecisionTreeClassifier (scikit-learn) - les colonnes comme entrées (X) - conform comme sortie (y)
Le modèle apprend automatiquement les règles.
Nous calculons aussi la précision (accuracy).
Objectif : apprendre une règle automatiquement à partir des données.
Gamma – Données bruitées (erreurs)
Dans la partie Gamma, nous cassons volontairement les données.
Principe : - on modifie les labels (conform) - on ajoute des erreurs (90%, 85%, 80%, …) - on réentraîne le modèle - on observe la baisse de performance
Objectif :
Montrer que la qualité des données est très importante en machine learning.
Conclusion
- Alpha : logique humaine
- Beta : apprentissage automatique
- Gamma : impact des erreurs
Ce projet montre qu’un modèle peut être correct, mais sans bonnes données, il apprend mal.
Liens
-
Code GitLab :
https://gitlab.com/ahmadola111-group/exo-octavia-python -
Documentation :
https://ahmad-docs-b3e3cc.gitlab.io/octavia/