Fake News RAG (Ollama + ChromaDB)
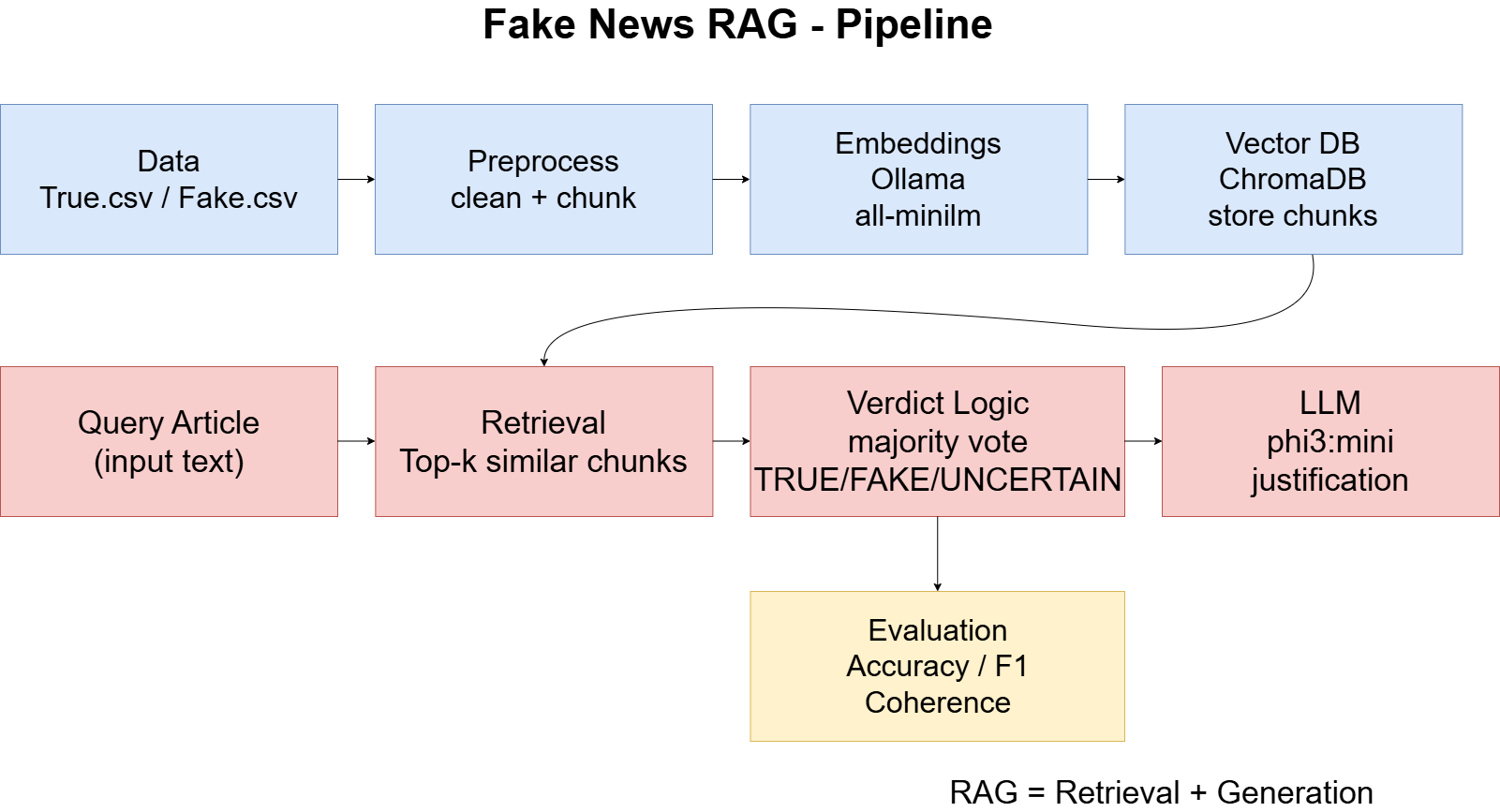
Ce projet implémente un pipeline RAG (Retrieval-Augmented Generation) pour détecter si un article est TRUE / FAKE / UNCERTAIN en comparant son contenu avec des articles de référence stockés dans une base vectorielle (ChromaDB). Le système récupère des passages similaires, décide un verdict par logique de récupération, puis génère une justification avec un LLM local (Ollama).
Objectifs
- Stocker des articles labellisés (True / Fake) dans une base vectorielle (ChromaDB)
- Retrouver les chunks les plus similaires pour un nouvel article
- Prédire un verdict (TRUE / FAKE / UNCERTAIN) via une logique de vote
- Générer une justification courte via un LLM local (Ollama)
- Évaluer les performances (Accuracy, F1, Coherence)
- Fournir une interface CLI et des notebooks
Architecture (Pipeline)
Le pipeline suit les étapes suivantes :
- Data loading (True.csv / Fake.csv)
- Cleaning + chunking (prétraitement texte)
- Embeddings (Ollama, ex: all-minilm)
- Stockage vectoriel (ChromaDB)
- Retrieval (top-k chunks similaires)
- Verdict (majority vote + logique de confiance)
- Justification (LLM local, ex: phi3:mini)
- Évaluation (Accuracy, F1, Retrieval coherence)
Technologies
- Python 3.12
- Ollama (LLM + embeddings)
- ChromaDB (vector database)
- pandas, scikit-learn
- Jupyter Notebook
- pytest
Modèles utilisés
- Embeddings → all-minilm
- LLM → phi3:mini
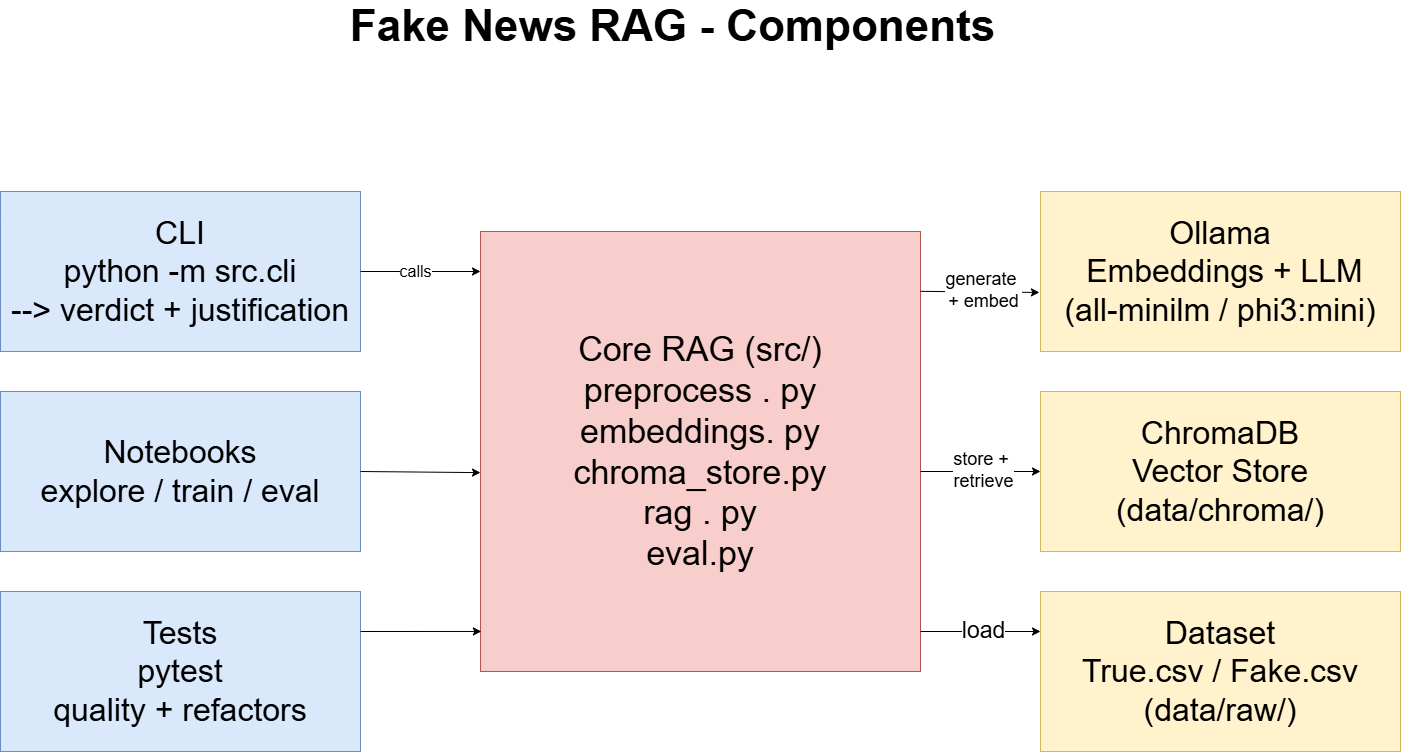
Structure du projet
fake-news-rag/
├── data/
│ ├── raw/ # True.csv / Fake.csv
│ └── chroma/ # Vector DB (généré, non commité)
├── notebooks/
│ ├── 01_explore_data.ipynb
│ ├── 02_preprocess_and_chunk.ipynb
│ ├── 03_build_chroma.ipynb
│ ├── 04_rag_prompt_test.ipynb
│ └── 05_eval.ipynb
├── src/
│ ├── preprocess.py
│ ├── embeddings.py
│ ├── chroma_store.py
│ ├── rag.py
│ ├── eval.py
│ └── cli.py
├── tests/
├── requirements.txt
└── README.md
Installation
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Démarrer Ollama + modèles
ollama serve
ollama pull all-minilm
ollama pull phi3:mini
Construire la base vectorielle (ChromaDB)
Cette étape : - nettoie les articles - découpe en chunks - calcule les embeddings - stocke dans ChromaDB
python -m src.build_index
Utiliser la CLI
python -m src.cli --text "Donald Trump is secretly replaced by a robot..."
Sortie : - verdict - confidence - justification - retrieved evidence (passages utilisés)
Évaluation
Ouvrir les notebooks :
python -m notebook
Puis exécuter : notebooks/05_eval.ipynb
Métriques : - Accuracy - F1 Score - Retrieval Coherence
Tests
python -m pytest -q
Limitations
- Verdict basé sur un vote majoritaire des chunks récupérés
- Le LLM est utilisé uniquement pour l’explication
- Les performances dépendent du dataset et de la qualité des embeddings
Améliorations possibles
- Dataset plus large
- Meilleure stratégie de chunking
- Calibration de la confiance
- Interface web (Streamlit)
- Classifieur fine-tuné
Liens
-
Dépôt GitLab :
https://gitlab.com/ahmad-training-2026/rag-pour-la-detection-de-fake-news/-/tree/main?ref_type=heads -
Portfolio :
https://ahmadaboalola.com/
Auteur
Ahmad Abo-Alola — Student AI Developer Project