Kevin et Mimi le Minotaure
Projet pédagogique en algorithmie, recherche de chemin et intelligence artificielle.
Objectif du projet
Créer un agent nommé Kevin capable de sortir d’un labyrinthe.
Le projet explore plusieurs approches :
- Génération de labyrinthes
- Algorithmes de recherche de chemin
- Apprentissage supervisé
- Apprentissage par renforcement
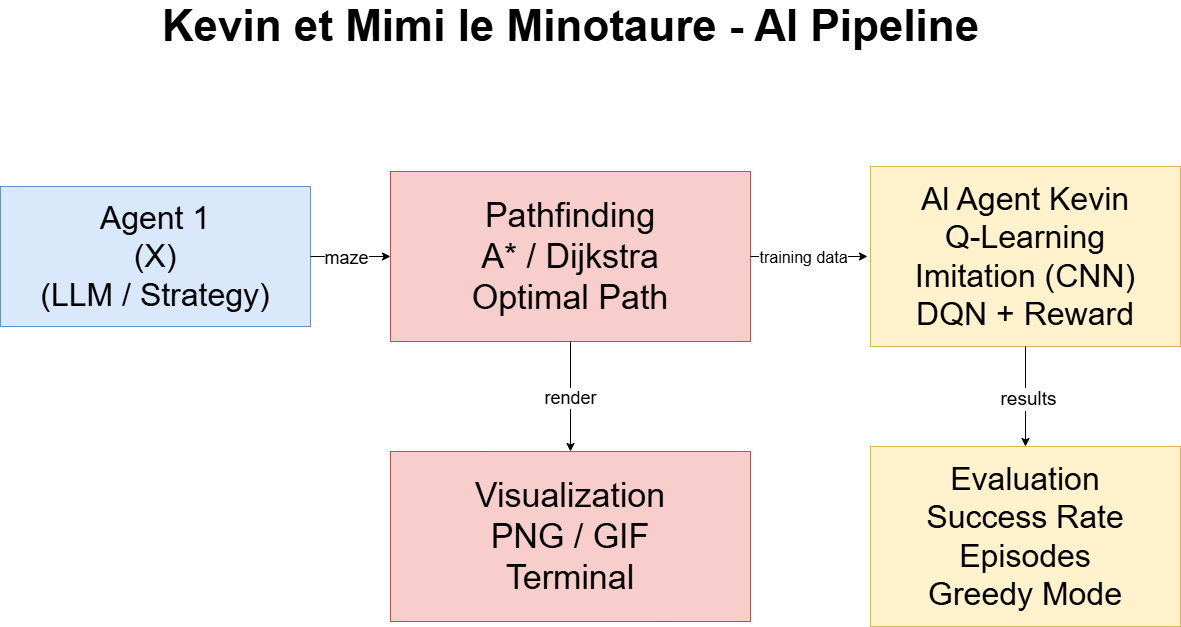
Génération des labyrinthes
Deux algorithmes sont utilisés :
DFS (Depth‑First Search)
Génération par exploration récursive avec backtracking.
Prim
Génération aléatoire basée sur l’extension progressive du labyrinthe.
Chaque labyrinthe contient : - une entrée (IN) - une sortie (OUT)
Résolution du labyrinthe
Deux algorithmes classiques sont implémentés :
- A* (algorithme heuristique)
- Dijkstra
Ils permettent de calculer le chemin optimal entre l’entrée et la sortie.
Intelligence artificielle
Plusieurs approches ont été testées :
Q-learning classique
- apprentissage très lent
- mauvais passage à l’échelle
- inefficace avec des labyrinthes variables
Imitation learning (Keras)
- Kevin apprend à imiter le chemin A*
- réseau convolutionnel (CNN)
- résultats limités (faible généralisation)
DQN avec reward shaping
- Deep Q-Network
- exploration ε-greedy
- replay buffer
- réseau cible (target network)
- récompenses basées sur le chemin A*
Cette approche donne les meilleurs résultats du projet.
Visualisation
Le projet permet de générer :
- Images PNG des labyrinthes
- Affichage terminal
- GIFs montrant Kevin en mouvement
- Chemin optimal en violet
- Entrée et sortie en couleur
Évaluation
Les modèles sont évalués sur plusieurs épisodes :
- Kevin joue sans hasard (mode greedy)
- Mesure du nombre de sorties réussies
- Comparaison avec le chemin optimal
Technologies utilisées
- Python
- NumPy
- TensorFlow / Keras
- Pillow
- Git & GitLab
Ce que j’ai appris
- Génération procédurale de labyrinthes
- Algorithmes de recherche de chemin (A*, Dijkstra)
- Apprentissage par imitation
- Deep Reinforcement Learning (DQN)
- Reward shaping et exploration
- Évaluation d’un agent intelligent
Améliorations possibles
- Environnement OpenAI Gym compatible
- Visualisation interactive web
- Optimisation GPU
- Multi‑agents (Kevin vs Minotaure)
Liens
-
Dépôt GitLab :
https://gitlab.com/ahmad-training-2026/kevin_et_mimi_le_minotaure/-/tree/main?ref_type=heads -
Portfolio :
https://ahmadaboalola.com/
Auteur
Ahmad Abo-Alola — Student Project (AI Developer Training)